
「硅基研究」是我们的一个新栏目,希望通过邀请行业内专家一起共创等方式,来分享最干货的研究和最一线的观察。希望在这里你能看到一些别的地方看不到的东西。
Hot Chips 是芯片领域最受关注,也最受重视的行业会议。各家芯片公司习惯于在这个会议上展示自己产品上最新的进展,因此它既是一个芯片技术发展的“剧透”大会,也是一个观察今天最重要芯片公司都在把研究重点投放到哪些方向的绝佳机会。 2024 年的 Hot Chips 刚刚在斯坦福大学落幕,英伟达等大厂展示了其产品细节,在大模型刺激下诞生的新公司们也借机秀了肌肉。我们邀请了参加了会议的资深硅谷芯片研发工程师,和我们分享了他的十点观察。
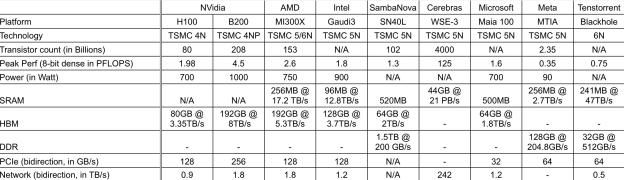
展示的 AI 加速器的芯⽚硬件能⼒总结在表格中。需要注意的是 ,一些能⼒已经进行了标准化处理 ,以便更公平地进行⽐较。例如 ,峰值性能显⽰了 8 位密集计算能⼒, PCIe/⽹络带宽为聚合的双向带宽。
由于⽣成式 AI 应用程序受到内存限制问题的影响 ,内存分层以及缓存和内存的大小至关重要。所有⼚商都尝试选择不同的优化点。
来自不同厂商的加速器架构相⽐之下更多相似点⽽⾮不同点。⼤多数架构包含专门处 理单元的阵列 ,并通过片上网络 (NoC) 进⾏扩展。很多架构引入不同粒度的Dataflow用于加速。
英伟达 (NVidia) vs AMD :英伟达仍然是唯⼀⼀家提供涵盖 CPU、GPU、NVswitch、 DPU、 NIC、以太⽹和 IB 交换机的全栈平台的公司 ,并且具备强⼤的软 件⽀持和丰富的⽣态系统。然而,AMD 的 Instinct MI300X 在硬件能力上非常令人印象深刻。ROCm 和系统级扩展将是 AMD 追赶英伟达的关键。
⼀家名为 Enfabric 的初创公司也宣布了他们的新型 SuperNIC ,它本质上是⼀种高阶路由器 ,集成了纵向扩展和横向扩展网络。每个纵向扩展端口是 PCIe ,每个横向 扩展端⼝是 RDMA, 通过内置的Switch进行All-to-all链接。通过合并endpoint和switch来提⾼密度 ,缩⼩footprint. idea⾮常独特 ,但很期待看到更多细节。
AMD、英特尔 (Intel)、⾼通 (Qualcomm)、 IBM 也展⽰了他们最新的CPU/SoC/FPGA。 除了扩展频率、寄存器、缓存和 I/O PG电子网站之外 ,许多 CPU 还开始增加小型 AI 加速器 ,并⽀持特殊指令来采⽤数据流 ,以提⾼性能并降低功耗。
英伟达 (Nvidia) 和新思科技 (Synopsys) 也展示了他们在芯片设计和制造过程中使⽤ AI 的⼀些最新进展。主要的使用案例包括 :
利用卷积神经⽹络 (CNN) 的模式识别能⼒ ,在物理设计过程中进⾏ IR drop 估 计 ,以加快分析速度。
利⽤图神经⽹络 (GNN) 的图探索能⼒ ,根据电路图预测布局寄⽣参数。
OpenAI 在主题演讲中再次强调了 AI 模型遵循可预测的扩展规律。假设模型架构足够优秀 ,数据PG电子网站量及其训练方式将决定模型的能⼒ 。因此 ,模型将会不断增⻓。
OpenAI 还强调 ,行业需要提供更强大且可靠的平台 ,以⽀持⼤规模 AI 基础设施的建设。